Optimizing a Go service at work
My recent adventure at work was an open-ended endeavour to optimize a memory guzzling Go service. The service is a cron job that is scheduled to run on an hourly basis. When it runs, it queries our Postgres DB, fetching a huge amount of data, applies some transformations on each row retrieved and writes the results to a CSV file. The CSV file is then compressed and uploaded to a SFTP server, from where our clients can download them and use them for their business needs. Simple enough, right?
Well, not quite. This service has been a memory hog since the get-go. When I started working on it, I decided to setup things locally first. While the setup itself was simple, it took me 3 tries just to get it working and generate some output. In the first 2 tries, it caused my system to run out of memory. When I finally did get it working on the 3rd try. I got my desired output - a 1 GB gzipped CSV file. And to generate it, it had caused my M3 Pro MacBook with 18 GB of RAM to go out of memory, twice. Yikes!
The Wake-up Call
Our service lives on a dedicated VM that started out with 16 GB of RAM. Onboarding new clients has always meant more memory usage. And so, it had been recently bumped up to 32 GB The service is a low-priority one, but is used by a lot of our clients. So, as we began to hit the upper bounds of memory usage, there were 2 discussions going on:
- The product team wanted to onboard new clients to this service, but couldn’t because the service wasn’t scaling so well.
- For both business and developers, this was a low-priority service, so nobody wanted to invest a huge time on it.
Initial Solution
Business needs couldn’t suffer just because our code couldn’t keep up with the requirements. So, we decided to try a few things first:
- Bump up the memory to 48 GB: Maybe it was time to go from 32 to 48 GB. This was the easiest thing to do, we could always add more resources to the VM that was running this service. However, as soon as we added a new client this time, we saw OOM killer triggering and the VM peaking at 95% memory usage, before finally crashing.
- Creating a dedicated instance: We decided to create a separate instance of this service and onboarding the new client to it. Surprisingly, this failed as well. We were still on 95% memory usage on a 48 GB VM with only 1 client. This meant that the memory load of this single new client data was too high to be handled by the VM.
“But it shouldn’t need gigabytes of memory to do simple things!” - Me, the new guy.
“Wanna have a go at it?” - Our Systems Architect.
“No harm in giving it a try.” - Me, the new guy.
And we’re back to the problem statement, where our service is crashing my MacBook. Twice. It was obvious to me that there probably was some unintended mistakes in the code that were causing it to be a memory hog. And so, given the go-ahead, I decided to try a few things.
Optimization - 1: Stream, Don’t Hoard
The service was grabbing the entire dataset from the DB in one shot, which pushed memory usage to a whopping 16.5 GB on my machine. So, I decided to process the data in a streaming manner rather than fetching it all at once. So, the following code:
1
2
3
4
5
6
7
8
9
10
11
db, err := sqlx.Connect("postgres", "user=foo dbname=bar sslmode=disable")
if err != nil {
log.Fatalln(err)
}
mystructArray := make([]MyStruct, 0)
_ := sqlx.SelectContext(ctx, db, mystructArray, "SELECT * FROM table")
// split the data into batches
// spawn a goroutine for each batch
became this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
db, err := sqlx.Connect("postgres", "user=foo dbname=bar sslmode=disable")
if err != nil {
log.Fatalln(err)
}
rows, err := db.QueryxContext(ctx, "SELECT * FROM large_table")
if err != nil {
log.Fatalln(err)
}
defer rows.Close()
for rows.Next() {
var row MyStruct
var rowBatch []MyStruct
if err := rows.StructScan(&row); err != nil {
log.Fatalln(err)
}
rowBatch = append(rowBatch, row)
if rowBatchSize == len(rowBatch) {
go processRowBatch(rowBatch)
rowBatch = rowBatch[:0]
}
}
I had expected this optimization itself to be the silver bullet that would fix this issue once and for all. However, the results weren’t so incredible. The peak memory usage reduced to around 10 GB, with a row batch size of 2000. The upside was that the service was no longer crashing my MacBook and would probably be good to deploy. But we still had miles to go.
Optimization - 2: Control the chaos with semaphores
A back of the paper math revealed that assuming a batch size of 2000 rows, the service would spawn 12,500 goroutines to process 25 million records.
While Go is incredibly good at handling a large number of goroutines, however, these goroutines were keeping the row batch in memory until they had finished processing. They were also keeping the generated output for each batch in memory till it was sent to be written to the CSV file.
Hence, there’s no use spawning so many goroutines at once. So, I decided to use semaphores to limit it to 2 x runtime.NumCPU(). And thus, the code became somewhat like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
rateLimitingSem := make(chan struct{}, 2 * runtime.NumCPU())
for rows.Next() {
var row MyStruct
var rowBatch []MyStruct
if err := rows.StructScan(&row); err != nil {
log.Fatalln(err)
}
rowBatch = append(rowBatch, row)
if rowBatchSize == len(rowBatch) {
rateLimitingSem <- struct{}{}
// spawn a goroutine for each batch
// Once, the batch is processed, release the semaphore
// from within the goroutine, using
// <-rateLimitingSem
go processRowBatch(rowBatch, rateLimitingSem)
rowBatch = rowBatch[:0]
}
}
This optimization was very effective. Not only did it reduce the peak memory usage to around 1.6 GB, it also reduced the total execution time by a minimum of 30 seconds (tested across 10 runs) - which was surprising to me. Why would limiting the concurrency improve execution time? I still haven’t found an answer backed by data, but my consultations with my fellow developers have led me to believe that we now had a reduced scheduling overhead.
Optimization - 3: Use buffered writers
Okay, so we had cut down memory usage to 1.6 GB, but that still felt like we were lugging around a suitcase full of bricks. I wasn’t going to rest until our RAM usage was in the MB range - because, you know, that’s where RAM usage belongs for a service like this!
While snooping around, I discovered we were using a bytes.Buffer to store results in memory before writing them to disk in one go. Granted in-memory buffers save you from wastefully making IO calls. But, whoever thought that was a good idea to write your entire data to an in-memory buffer before writing it to disk?
Switching to a BufferedWriter with a 10 MB buffer was a game-changer, it added an extra 1.5 seconds to the running time of the service. It also slashed the memory usage from 1.6 GB to just 50 MB.
The Code Review Meeting
Good teams have well-established code-review processes. In our cases, 2 developers must review and approve your PR before it can be accepted into the main branch. If your changes are big enough that you must explain them to the people reviewing them, you can have a meeting to discuss them.
In my case, when I shared an update of the memory savings I had made in the daily standup meeting, my manager, the ever skeptic, asked me to setup a review meeting to discuss my changes.
And thus, I did. And wrote this entire analysis as part of it. In order to prove that my improvements hadn’t messed up anything, I also shared a comparison of the MD5 hashes of the old and new files, which were an exact match, crashing my machine once more in getting the old version of code to run. That was the mic drop moment - everything was working as expected!
Post deployment
Once the service was deployed to production, it was time for checking out how much we had actually improved. The old service was running on a 48 GB VM with 90% peak memory usage (new client hadn’t been onboarded yet). The new service was running on the same VM with the new client onboarded. Here’s a graph of the memory usage pre and post-deployment:
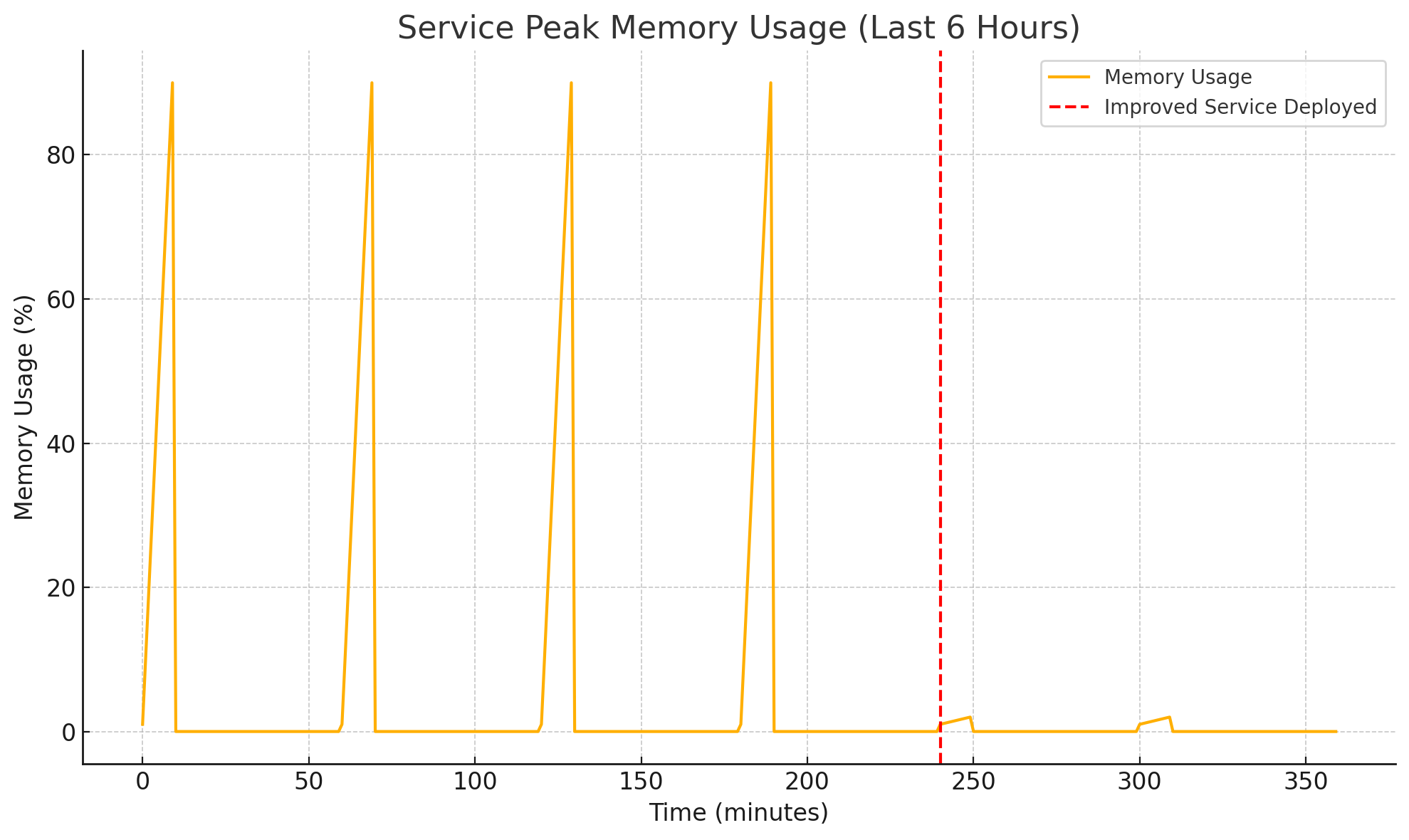
The service had a configurable concurrency setting that controlled how many queries it would make at once for processing data for the clients. So far, we had limited that to 1 because setting this to 2 or more would cause it to go out of memory. But now, we could crank it up as much as we wanted to. And so, a value of 8 was agreed upon and we saw the execution time go down from 10 minutes to mere 1.5 minutes. And the memory usage has now gone from 90% to under 2%.
And this kids, is how I improved our go service, transforming it from a memory-guzzling monster into an efficient and a scalable beast.